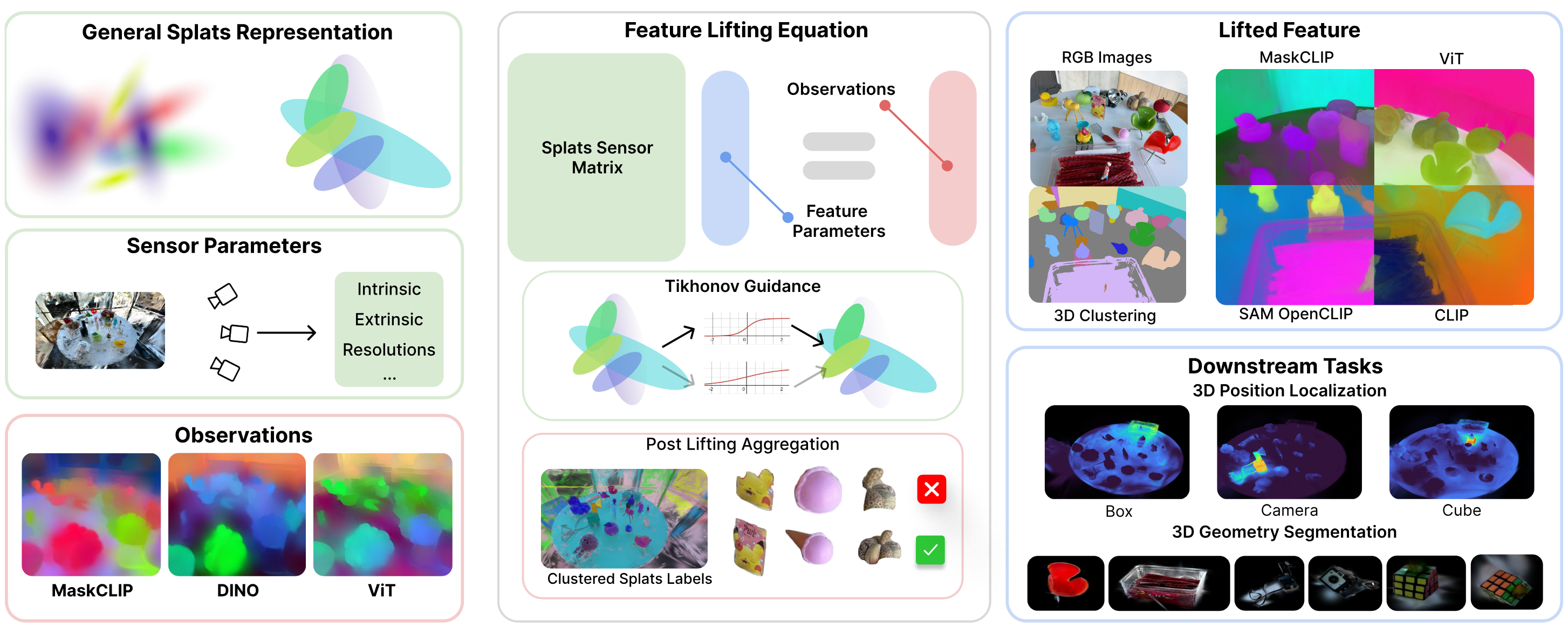
Feature lifting has emerged as a crucial component in 3D scene understanding, enabling the attachment of rich image feature descriptors (e.g., DINO, CLIP) onto splat-based 3D representations. The core challenge lies in optimally assigning rich general attributes to 3D primitives while addressing the inconsistency issues from multi-view images. We present a unified, kernel- and feature-agnostic formulation of the feature lifting problem as a sparse linear inverse problem, which can be solved efficiently in closed form. Our approach admits a provable upper bound on the global optimal error under convex losses for delivering high quality lifted features. To address inconsistencies and noise in multi-view observations, we introduce two complementary regularization strategies to stabilize the solution and enhance semantic fidelity. Tikhonov Guidance enforces numerical stability through soft diagonal dominance, while Post-Lifting Aggregation filters noisy inputs via feature clustering. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on open-vocabulary 3D segmentation benchmarks, outperforming training-based, grouping-based, and heuristic-forward baselines while producing the lifted features in minutes.
Row Sum Pre-Conditioner
The row sum pre-conditioner has been discovered independently by
CosegGaussian,
OccamLGS,
as well as
DrSplat.
The Intuition behind it could be summarized as a weighted sum according to the contribution of the
splats to the final rendering features. When the splats' geometry is fixed, that contribution is
agnostic to the feature type.
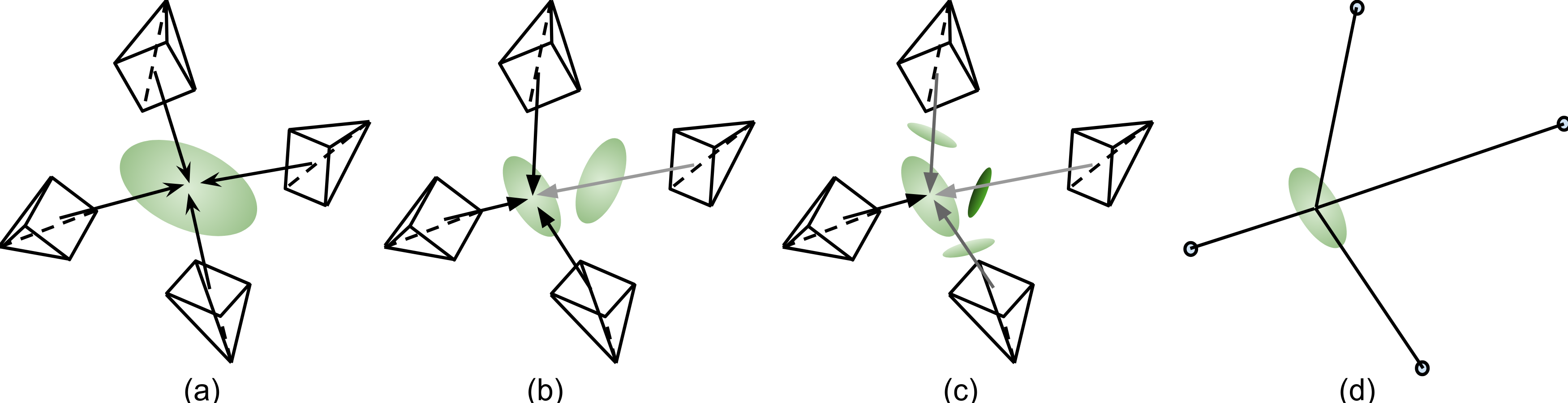
We consider a simple scene with a single Gaussian and multiple cameras viewing it. The goal is to assign an
attribute to that Gaussian so as to minimize the L2 loss for each camera. The optimal solution is simply the
average of the four camera features. In subfigure~(b), we introduce a second Gaussian that blocks one view;
intuitively, the optimal feature for the target Gaussian should be closer to the features of the three unblocked cameras,
while the occluding Gaussian should match the rightmost camera’s feature. When multiple Gaussians with different alpha
values are present (subfigure~(c)), each target feature becomes a weighted average of the corresponding camera features,
as illustrated in subfigure~(d). Interestingly, computing these weights is equivalent to performing a forward rendering pass.
This key insight makes the row sum pre-condtioner a fast approximation
Feature Lifting Problem
We define the feature lifting problem as a sparse linear inverse problem. The goal is to assign an
attribute to each primitive so as to minimize the convex loss for the feature lifting equation. To
construct that matrix, we only need to know the contribution of each primitive to the final rendering
results, as well as the sensor parameters. Therefore, in the above definition, feature lifting problem
is agnostic to the feature type, and the primitive kernel. We also prove that the row sum pre-conditioner
has a provable upper bound of the feature lifting problem. And we proposed two complementary regularization
strategies to stabilize the solution and enhance semantic fidelity. Tikhonov Guidance enforces numerical stability
through soft diagonal dominance, while Post-Lifting Aggregation filters noisy inputs via feature clustering.
Feature Visualization
To visualize the feature lifting results, we use PCA to reduce the feature dimension to 3D and display with colors.
Click anywhere to play/pause. Drag the vertical bars to reveal different videos.
After the first lifting procedure, we provide a post-filtering aggregation to further refine the results. The intuition is to
filter out the unreliable masks generated by SAM. And emphasizing the diagnoal mask. During the aggregation, we conducted a scene
decomposition to quantize the features. Thereby providing more reasonable segmentation results.
Click anywhere to play/pause. Drag the vertical bars to reveal different videos.
We then apply the segmentation by contrasting the query word attention score with background attention score.
And use a default threshold 0.0 to generate the segmentation results.
Click anywhere to play/pause. Drag the vertical bars to reveal different videos.
@misc{xiong2025splatfeaturesolver,
title={Splat Feature Solver},
author={Butian Xiong and Rong Liu and Kenneth Xu and Meida Chen and Andrew Feng},
year={2025},
eprint={2508.12216},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.12216},
}